Kurz und knapp: Aria2 ist ein Downloadmanager für Linux, welcher ein sehr großes Funktionsspektrum bietet – Downloads werden per HTTP/HTTPS, FTP, BitTorrent oder Metalink abgewickelt. Im HTTP-Bereich ist es möglich Downloads in mehrere Parts zu stückeln und diese von verschiedenen Mirror-Servern zu laden.
In meinem Fall soll das Ganze auf einem (GUI-losen) Linux-System laufen und von einem PC verwaltbar sein – so kann z.B. die neue Linux-Distro gemächlich über meine alte DSL-Leitung vor sich hin laden ohne meine Kabel-Hauptleitung zu belasten oder mich zu Zwingen den Rechner durchlaufen zu lassen. Als Host genügt dabei durchaus ein Linux-Embedded-System wie z.B. viele Router oder auch der Raspberry Pi.
Aria2 findet sich in den offiziellen Arch-Repos und lässt sich entsprechend direkt installieren. Für den Daemon-Modus nutze ich einen eigenen Benutzer namens „aria2“. Im Home-Verzeichnis des Nutzers wird (wenn nicht vorhanden) ein Ordner .aria2 erstellt (führenden Punkt nicht vergessen). Dort wiederum eine Datei namens aria2.daemon mit folgendem Inhalt:
continue
daemon=true
dir=/home/aria2/Downloads
file-allocation=falloc
log-level=warn
max-connection-per-server=4
max-concurrent-downloads=3
max-overall-download-limit=0
min-split-size=5M
enable-http-pipelining=true
enable-rpc=true
rpc-listen-all=true
rpc-user=rpcuser
rpc-passwd=rpcpass
Die Konfiguration weist Aria2 an als Daemon zu starten und alle Downloads in /home/aria2/Downloads zu speichern. Pro Server werden maximal 4 Verbindungen geöffnet, insgesamt 3 Downloads werden parallel geladen. Eine Bandbreitenbeschränkung für den Download ist nicht hinterlegt. In den letzten Zeilen werden die Zugangsdaten für das Frontend hinterlegt.
Anm: rpc-user und rpc-pass sind „deprecated“ und sollten nicht mehr verwendet werden, zum aktuellen Zeitpunkt wurde das hier verwendete Frontend jedoch noch nicht auf die neue Authentifizierungsmethode portiert
Anm2: file-allocation=falloc weist aria2 an den für den Download nötigen Platz im Vorfeld zu reservieren, dies verhindert Fragmentierung der Daten, jedoch kann es beim Start des Download einige Sekunden bis Minuten dauern bis die ersten Daten übertragen werden. falloc ist nur auf neueren Dateisystemen wie ext4, btrfs oder xfs nutzbar, bei älteren Systemen kann prealloc genutzt werden. Mit none wird die Reservierung abgeschaltet.
Um den Daemon automatisch beim Boot zu starten wird zudem die Datei /etc/systemd/system/aria2c.service erstellt:
[Unit]
Description=Aria2c download manager
After=network.target
[Service]
Type=forking
User=aria2
RemainAfterExit=yes
ExecStart=/usr/bin/aria2c --conf-path=/home/aria2/.aria2/aria2.daemon
[Install]
WantedBy=multi-user.target
Auch hier ggf. die Pfade an das eigene Setup anpassen.
Per systemctl start aria2c wird der Dienst gestartet – läuft dies ohne Fehlermeldung kann er mit systemctl enable aria2c in den „Autostart“ des Servers gelegt werden. Alles ist auch nochmal in der Arch-Wiki zu finden.
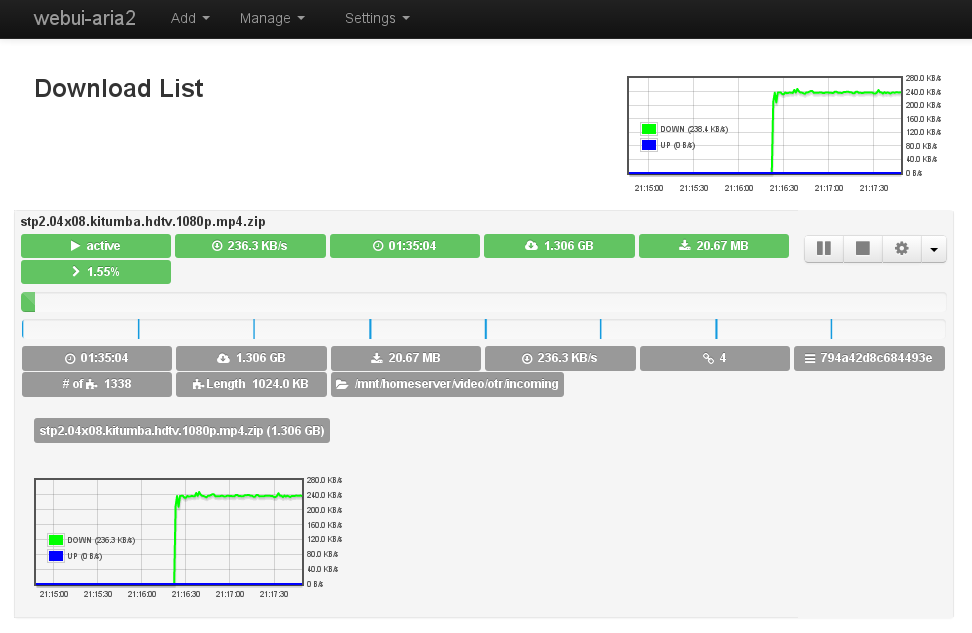
Für das Webinterface verwende ich webui-aria2. Es nutzt ausschließlich Javascript/HTML5 (Websockets/AJAX) für die Kommunikation, daher ist es weder notwendig die Daten auf dem selben System abzulegen, PHP/Python/Perl… zu installieren oder einen Webserver zu nutzen. Theoretisch kann die Datei auf der lokalen Festplatte des verwaltenden PCs/Laptops liegen und dort geöffnet werden. In meinem Fall liegen die Dateien auf einem bereits vorhandenen Webserver, so muss ich bei Updates nicht immer zwischen all meinen Geräten hin und her kopieren.
Beim öffnen der HTML-Datei werden die Zugangsparameter abgefragt. Bei Host wird die IP des Servers mit Aria2 eingetragen, der Port ist bereits hinterlegt. User/Passwort wurden in der zuvor erstellten Konfigurationsdatei eingerichtet.
Im Anschluss sollte die Verbindung aufgebaut werden können – am besten Prüft man das über Settings->Server Info, sind hier Daten hinterlegt konnte die Verbindung aufgebaut werden. Lasset die Downloads starten!
Bild: https://adlerweb.info/blog/wp-content/uploads/2014/05/aria2-300×195.png
Downloads direkt auf einem kleinen Linux-System? Check.
Zur Referenz: Der gezeigte Download ist Star Trek Phase II: Kitumba von startrekphase2.de.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}